Codeforces Learner
Intro
The goal of our project was to extract labels from a set of coding competition problems found from codeforces.com. We chose this website in particular because this website has the most problems, and the format of the website makes it simple to extract text from. We hope to identify problems of a certain type by learning the sentence structure and wording of 36 different problem types.
We use a Long Short Term Memory Network (LSTM) to model our data because LSTMs are great for learning patterns over time by continually feeding input data into a neural network as well as output from the previous step. In this way, it learns sequences of sentence patterns. One challenge we had to overcome in our project was how to represent the input, because each problem may have many or no tags. Initially, we wanted to make a multiclass network, but binary classification for each label seemed to work best.
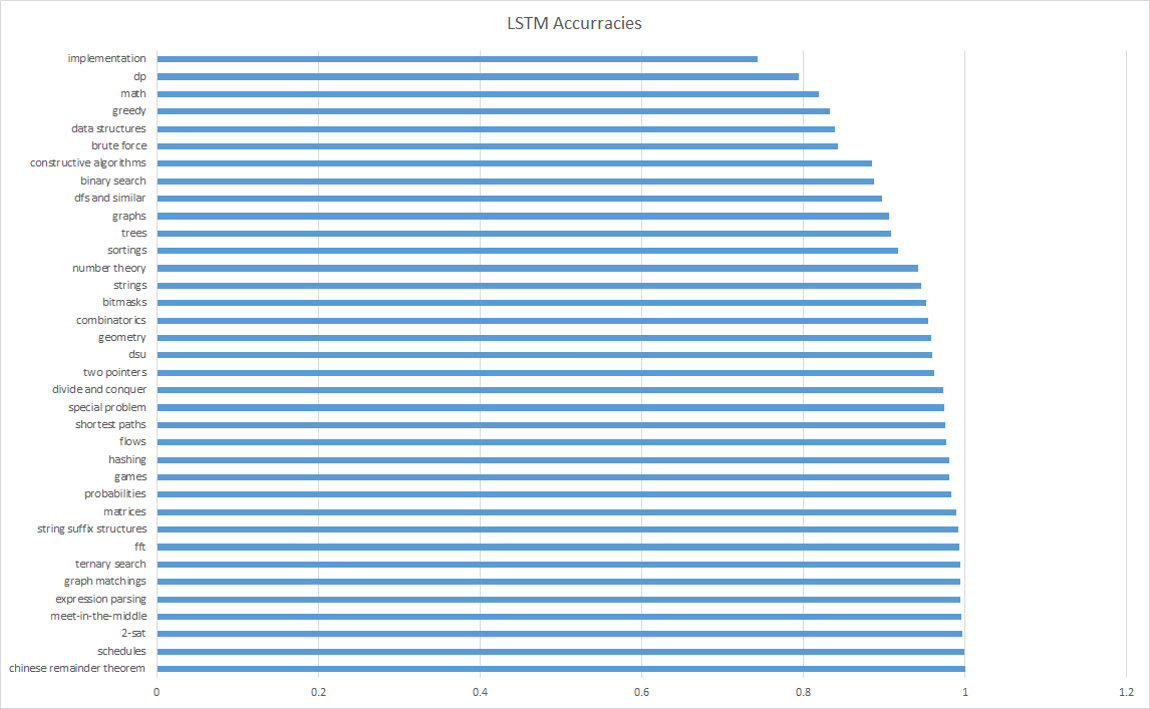
As a result of our LSTM, we were able to learn tags 5% better than guessing random. In the future, we recommend sampling from a larger data set, as ours was composed of about 4000 problems, with some tags having as little as 5-10 problems. In addition, we recommend having a balanced number of problems per tag. A common problem we faced was our LSTM always getting “false” for every label, due to the few incidences of each label. For this reason, we compared our LSTM results to the ratio of the number of occurrences of a tag in our dataset. Our best result was our LSTM guessing one of the most common tags, “implementation”, which guessed 5% better than guessing “false” every time.
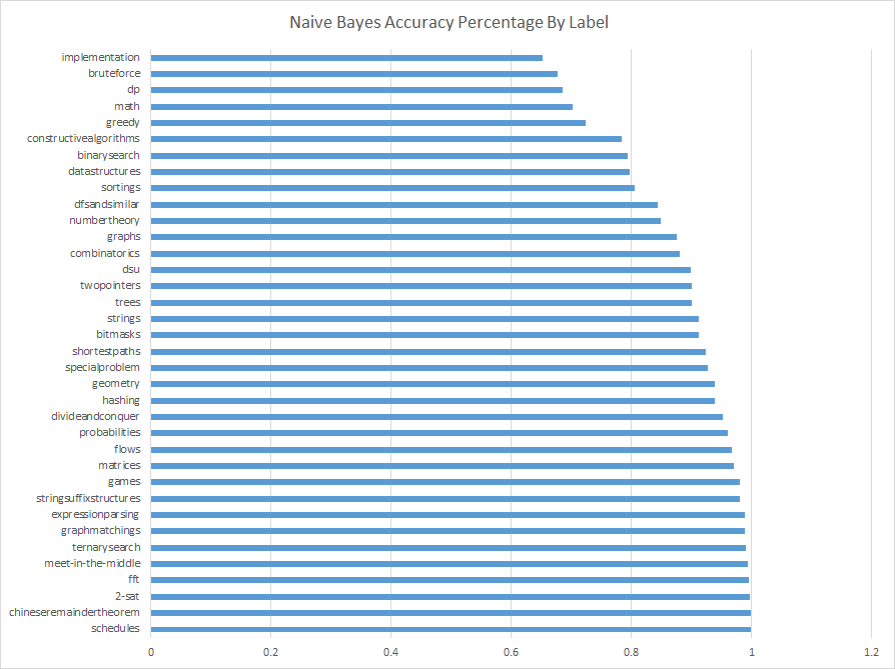
We created a Naive Bayes model to compare to our LSTM results, which used TF-IDF to preprocess the words. We found that our LSTM did significantly better than Naive Bayes, with better accuracy. The LSTM also did much better when compared to the distribution of tags among our data.
In addition, we also recommend studying graphical models as a way to represent the tag relationships, because many of the tags are related. For example, the LSTM may identify a problem as “trees” when the actual tag may be “binary search”. We could alter the loss function to penalize similar tags to a lesser degree.
We also recommend trying to guess the “Difficulty Level” of a problem. Coding problems on other websites are often rated on a scale from 1-10, in order of difficulty. We feel that this may yield more consistent results, due to having a larger and continuous data set.
Our LSTM results:
 Our Naive Bayes Results:
Our Naive Bayes Results:
Methods
LSTM (Long Short Term Memory RNN)
We used a keras implementation LSTM in order to predict tags for the codeforce problems. Keras uses a tensorflow backend, but is a useful wrapper to use to make it easier.
Our initial implementation in LSTM.ipynb tried to do multiclass prediction for predicting tags for a codeforces problem. The results were pretty miserable, getting a .9% correctness. This caused us to try a new strategy: we created a seperate LSTM for each tag in our dataset. Our input to the LSTM were individual words in the problem statement for the codeforce problems. We vectorized the problem statement, and fed each word recurrently into each new cycle of the Recurrent Neural Network. We trained it on the final output prediction, judging its correctness by either saying that it was or was not actually a part of that tag group.
Our results outperformed Naive Bayes significantly. The ‘implementation’ tag and the ‘suffix-string’ tag were both being predicted with 5% improvement over the baseline prediction. This is significant because the ‘implementation’ tag is the highest occurring tag. This may suggest that if we had more data for other tags, we may be able to predict them with more accuracy. However, despite our efforts to deal with our lack of data, we still weren’t able to do much better than randomly guessing the tag for a codeforces problem. With more data to supplement our LSTM, we believe that our accuracy would improve markedly.
Raw text extraction
To load all problems, see the util.loadAllProblems() function. This will parse the raw html from the scraper output into a set of problem objects.
The problem object contains many fields, but we did not end up using all of them. Of course, the most important field is the one that contains a list of tags for the problem. For features, we decided to concentrate primarily on the text fields, including ‘title’, ‘main_text’, ‘input’, and ‘output’. We removed unicode characters and special characters, and put all the text into a long block for each problem. This was the raw data for each problem, but we refined it into a more useful feature vector, which is described next.
TF-IDF
Extracting useful features from a document can be challenging. One obvious option would be to count the occurrences of each word and use those counts as the features. A possible concern with this problem with this is that some words may occur very frequently in all documents, and thus have very little meaning. Examples are words like ‘the’ or ‘and’. Instead, we used TF-IDF, which stands for “term frequency - inverse document frequency”. This looks at the entire dataset and weights a word’s ‘usefulness’ based on how many times it appears in the document (the TF), but decreases the weight of the word if it appears in many of the documents. Words that appear very frequently in one document but infrequently in others would tend to have a high weight. TF-IDF outputs a useful feature vector for each problem that we feed into other learning algorithms.
Bernoulli Naive Bayes
To run our Bernoulli Naive Bayes, use $ python naive_bayes.py. This will execute a separate learning and testing algorithm on each tag. The code uses K-fold cross validation on each tag. The evaluation accuracy is whether or not the trained naive_bayes learner correctly guesses ‘yes’ or ‘no’ as to whether each problem in the testing set has a tag or not.
To start with, we used only the problem tags from the Codeforces website. However, we found that both naive_bayes, and later the neural network, tend to learn to guess ‘no’ most of the time for uncommon tags. While this achieves a high ‘accuracy’, it is obviously not very interesting. By decreasing the learning rate, the naive bayes guesses ‘yes’ more often but, as a result, achieves a lower accuracy. For most tags, the final accuracy is comparable to the number of problems that do not have the tag. For uncommon tags, such as ones like ‘chineseremaindertheorem’ with only about 10 occurrences, there is little we can do about this behavior; there is not enough data. These tags could be ignored entirely.
Even with tags that occur more than 10% of the time, this behavior is still present. To mitigate this, we decided to create ‘custom’ tags groups that, more or less, combine related tags together. As an example, we made a new tag, ‘all_math’ which is assigned to every problem with any one of the following math-related tags.
[‘math’, ‘numbertheory’, ‘combinatorics’, ‘geometry’, ‘probabilities’, ‘matrices’, ‘fft’]
This ‘all_math’ tag occurs %30 of the time, which at least gives us a way to evaluate a few more balanced tags. With the common custom tags, the naive_bayes learner improves over “randomly guessing” by a couple of percentage points, which is not very significant.
Setup
Glibc
This project requires glibc version >= 2.16. To check which version you have, run
$ ldd --version
If you don’t have the correct version, I recommend running this software on a different computer. Updating glibc is a long and painful process, and has the potential to mess things up on your computer. However, if you do want to update glibc, there are many tutorials online, and it can differ per operating system. This project worked on Windows 10, using Anaconda, but did not work on CentOS 6.8, using Anaconda.
Anaconda
We recommend you use Anaconda to run this project. Download here: https://www.anaconda.com/download/
Python
Requires Python 3, recommended use is Python 3.5. We also recommend you use a virtual environment to download requirements and run. To set up a virtual environment, run
(via Anaconda shell)
$ conda create -n python3.5 python=3.5
Then to activate the python virtual environment, run
(in Anaconda shell)
$ activate python3.5
(or alternatively, in bash shell)
$ source activate python3.5
If you would like to deactivate the virtual environment, run
$ deactivate
Install dependencies:
While your python virtual environment is activated, run
$ pip install -r requirements
Training the Neural Network
To run, activate your python virtual environment and open jupyter notebook from an Anaconda shell. Note that if you are running this through a laptop, the training runs significantly faster if your laptop is plugged into a power source.
(in Anaconda shell)
$ activate python3.5
$ jupyter notebook
This should open up a browser window for jupyter notebook. Open up please_work.ipynb and step through every code block.
##Codeforces Scraper info. The codebase obtains the Codeforces problems by using the BeautifulSoup library. Some instructions are below.
Running the Scraper
This should not be necessary because we already have a database in our github repo. However, if you want to download the latest Codeforces data, this is how you scrape the data.
NOTE: Running the scraper may be very disruptive towards Codeforces contests hosted on the website!! In order to not be a jerk, please check http://codeforces.com/contests/ to ensure that there is currently not a contest going on. Also note that the start time listed on the website may not be in your time zone. Click on the DATE itself (i.e. “Dec/12/2017 10:05UTC-5”) to view when the contest has started in YOUR timezone.
This should download every html page to every problem on Codeforces to directory called “texts” in your current directory. Within “texts”, the files will be organized in subdirectories based on the contest.
NOTE: When running the scraper, please do not run during peak hours (i.e., especially not during or near the time of a Codeforces contest). The site experiences a lot of load during the contests as is. Also, the scraper would almost certainly run slower as well.
To avoid running the scraper unnecessarily, a zip file with the first 3800 or so problems is included in the repo. Of course, recent and future problems are not included.
problem.py contains a class object that will represent fields for a single problem.